Load balancing is one of the technologies that virtually all our customers are using within EC2, and there is an increasing set of options available for doing it. We’ve been giving advice to our customers for years on what we’ve seen work but we finally decided to spend some time and do a real A-B benchmark comparison of a number of solutions.
The test we ran compared the following solutions:
- HAproxy on an EC2 instance
- Zeus on an EC2 instances
- aiCache on an EC2 instance
- Amazon’s Elastic Load Balancing service
We focused purely on request rate scalability – that is, how many requests per second the load balancer can sustain. We didn’t focus on feature set, bandwidth, or other metrics. So we ended up requesting a tiny web page over and over as fast as the system under test would serve up and we measure requests/second, or rather, responses/second. We also didn’t take advantage of more advanced features, such as caching in the load balancers, so we ran aiCache in a pure LB mode, for example.
Cutting to the chase, we ran the HAproxy, Zeus, and aiCache tests on an m1.large EC2 instance. After chasing down all kinds of options, trying to tune the kernel, trying other instance types, and finally conferring with AWS—the result is 100,000 packets per second in+out! I know, that’s not requests/sec or responses/sec so let me explain. Basically, with the current virtualization technology implemented in EC2 the network speed of light on an instance is getting about 100,000 packets per second through the two networking stacks of the host OS and the guest OS. Your load balancing solution and the tests you run may use these 100K pps to requests and responses in various ways which give you slightly different performance as measured in resp/sec. On average you can get about 5000 requests/sec through a load balancer. If you use HTTP1.1 persistent connections you get a few more resp/sec because there are a couple fewer packets per request, but the difference is not all that dramatic. If you turn some form of caching on you can roughly double the resp/sec because you’re eliminating the packets to the back-end servers. Tuning kernel params has very little effect, but pinning the load balancer process to a specific core does help quite a bit and makes the performance a lot more even. But in the end it’s all about pps (packets per second).
![]()
Cloud Management
Take control of cloud use with out-of-the-box and customized policies to automate cost governance, operations, security and compliance.
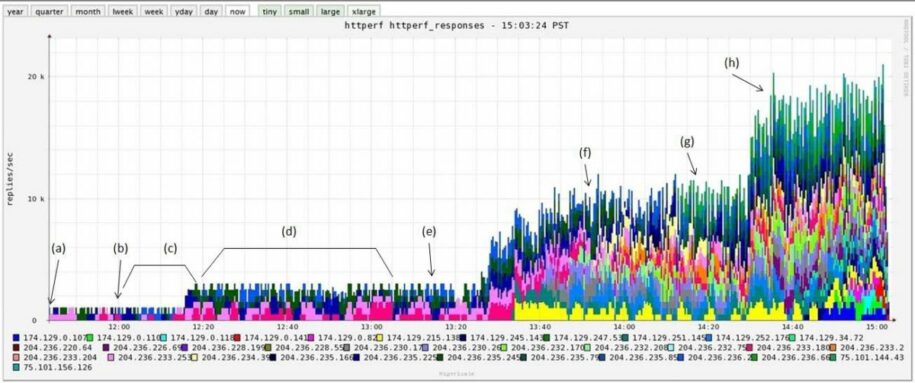
We then turned to ELB, the Amazon Load Balancing service. It operates differently from the other solutions in that it is a scalable service provided by Amazon. Everything ELB does for you can be replicated using the above solutions running on EC2 instances, but of course that requires extra work. Unfortunately benchmarking ELB is really tricky. One has to use many clients applying load, ensure that they requery DNS frequently, and run tests for a long time so ELB scales up. In the end we produced some pretty graphs like this, showing the requests/sec handled over time:

This shows how our tests ramped up to around 20K requests/sec over the course of about three hours. (Note that we ramped up the load slowly to see the progress, so this is not all time taken by ELB to ramp up.) We could have continued higher but we lost interest :-). I would prefer it if ELB were more transparent and easier to test, but it certainly delivers real-world performance!
The whole benchmarking project was interesting in that it once again showed that until you really understand what is going on your benchmark is not done. We chased down more supposed performance bottlenecks than we care to remember and we drove the helpful folks at aiCache batty because they expected to see better performance given their results on non-virtualized machines. But in the end the results make a lot of sense and 100K pps is easy to remember.




